An Introduction to Amazon EventBridge
Amazon EventBridge is a fully managed serverless event bus that allows you to send events from multiple event producers, apply event filtering to detect events, perform data transformation where needed, and route events to one or more target applications or services (see Figure 3-39). It’s one of the core fully managed and serverless services from AWS that plays a pivotal role in architecting and building event-driven applications. As an architect or a developer, familiarity with the features and capabilities of EventBridge is crucial. If you are already familiar with EventBridge and its capabilities, you may skip this section.
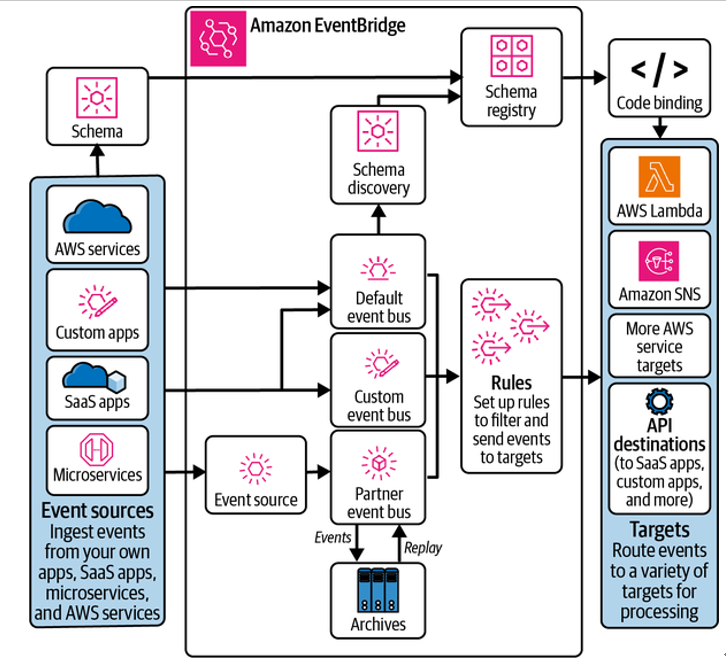
Figure 3-39. The components of Amazon EventBridge (source: adapted from an image on the Amazon EventBridge web page)
The technical ecosystem of EventBridge can be divided into two main categories. The first comprises its primary functionality, such as:
- The interface for ingesting events from various sources (applications and services)
- The interface for delivering events to configured target applications or services (consumers)
- Support for multiple custom event buses as event transportation channels
- The ability to configure rules to identify events and route them to one or more targets
The second consists of features that are auxiliary (but still important), including:
- Support for archiving and replaying events
- The event schema registry
- EventBridge Scheduler for scheduling tasks on a one-time or recurring basis
- EventBridge Pipes for one-to-one event transport needs
Let’s take a look at some of these items, to give you an idea of how to get started with EventBridge.
Event buses in Amazon EventBridge
Every event sent to EventBridge is associated with an event bus. If you consider EventBridge as the overall event router ecosystem, then event buses are individual channels of event flow. Event producers choose which bus to send the events to, and you configure event routing on each bus.
The EventBridge service in every AWS account has a default event bus. AWS uses the default bus for all events from several of its services.
You can also create one or more custom event buses for your needs. In addition, to receive events from AWS EventBridge partners, you can configure a partner event source and send events to a partner event bus.