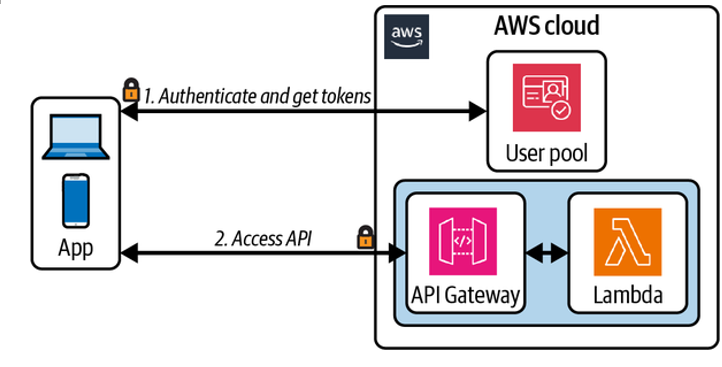
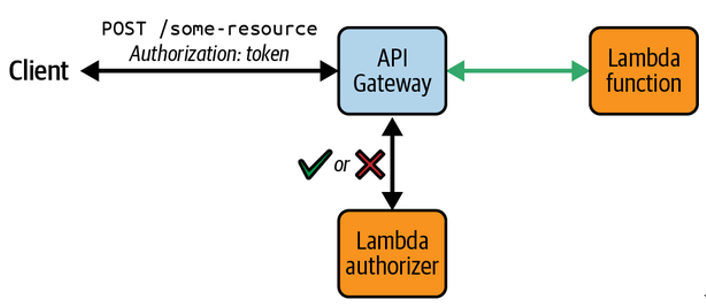
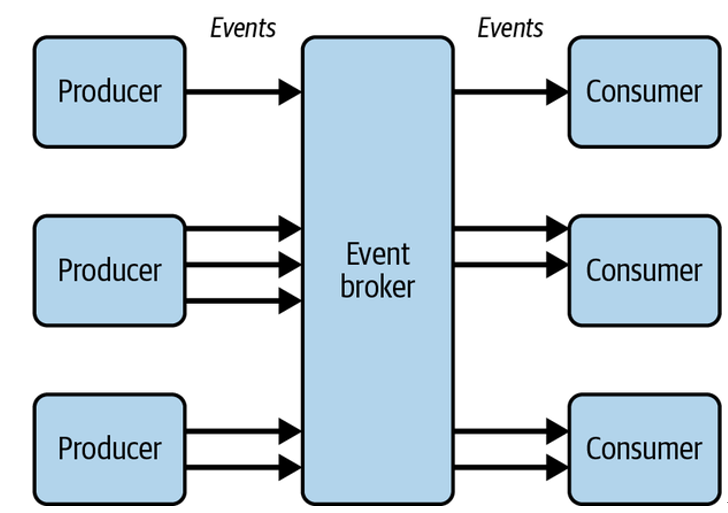
Scan packages for vulnerabilities
You should also run continuous vulnerability scans in response to new packages, package upgrades, and reports of new vulnerabilities. Scans can be run against a code repository using tools such as Snyk or GitHub’s native Dependabot alerts system.
Automate dependency upgrades
Out of all the suggestions for securing your supply chain, this is the most crucial. Even if you have a serverless application with copious packages distributed across multiple services, make sure upgrades of all dependencies are automated.
Warning
While automating upgrades of your application’s dependencies is generally a recommended practice, you should always keep in mind the “think before you install” checklist from the previous section. You should be particularly mindful of the integrity of the incoming updates, in case a bad actor has published a malicious version of a package.
Keeping package versions up-to-date ensures that you not only have access to the latest features but, crucially, to the latest security patches. Vulnerabilities can be found in earlier versions of software after many later versions have been published. Navigating an upgrade across several minor versions can be difficult enough, depending on the features of the package, the adherence to semantic versioning by the authors, and the prevalence of the package throughout your codebase—but upgrading from one major version to another is typically not trivial, given the likelihood of the next version containing breaking changes that affect your usage of the package.
Runtime updates
As well as dependency upgrades, it is highly recommended to keep up-to-date with the latest version of the AWS Lambda runtime you are using. Make sure you are subscribed to news about runtime support and upgrade as soon as possible.
Warning
By default, AWS will automatically update the runtime of your Lambda functions with any patch versions that are released. Additionally, you have the option to control when the runtime of your functions is updated through Lambda’s runtime management controls.
These controls are primarily useful for mitigating the rare occurrence of bugs caused by a runtime patch version that is incompatible with your function’s code. But, as these patch versions will likely include security updates, you should use these controls with caution. It is usually safest to keep your functions running on the latest version of the runtime.
The same is true for any delivery pipelines you maintain, as these will likely run on virtual machines and runtimes provided by the third party. And remember, you do not need to use the same runtime version across pipelines and functions. For example, you should use the latest version of Node.js in your pipelines even before it is supported by the Lambda runtime.